
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 데이터 해저드
- Design DNN Accelerator
- CLOCK GATING
- DNN Accelerator
- gpgpu-sim
- 남산업힐
- Pyverilog 실행
- Makefile compile
- CDC
- pyverilog 설치 오류
- pygraphviz 설치 오류
- 컨벌루션 연산
- linux c 컴파일
- 대구 반도체 설계기업 특화
- Data HAzard
- systolic array
- Pyverilog 튜토리얼
- AMBA
- Pyvrilog tutorial
- CUDA
- makefile
- pytest-pythonpath 설치 오류
- 딥러닝 가속기
- DNN 가속기
- gcc 컴파일
- linux c++ 컴파일
- Pyverilog 설치
- 이진수 곱셈 알고리즘
- linux makefile 작성
- 클럭 게이팅
- Today
- Total
오늘은 맑음
Study note : Efficient Processing of Deep Neural Networks(5) 본문
5.5 TECHNIQUES TO REDUCE REUSE DISTANCE
이번 장에서는 5.4장에서 다루었던 reuse distance를 줄이는 방법에 대해 다룹니다. Reuse distance는 temporal reuse와 spatial reuse에 영향을 끼치기 때문에 다양한 방법으로 reuse distance를 조절하여 고정된 hardware에서 서로 다른 layer들을 가장 효율적으로 연산할 필요가 있기 때문입니다.
먼저 data tiling에 대해서 설명합니다. Data tiling이란 큰 데이터를 'tile'이라는 작은 단위로 나누는 것을 의미합니다. Tile단위로 나누게 되면 한 번에 큰 데이터를 한 번에 처리 할 필요 없이 각 tile에 대해서만 처리가 가능해집니다. 5.5장에서는 data tiling을 통해 reuse distance를 줄이고자 합니다.

예를 들면, 이 전 장에서 보여주었던 5.2(c)를 보게 되면 reuse distance가 1입니다. 본 장에서는 reuse data를 줄이겠다고 했는데, 이미 reuse distance가 1임을 보여주었네요. Weight 역시 0, 1, 2, 3 총 네 번만 읽어도 재사용으로 인해 모든 input activation을 연산할 수 있습니다. 하지만 여기서 문제가 발생하는데, output activation을 연산하기 위해서 필요한 memory가 총 4개가 필요하게 됩니다. 책에서 표현하기로는 partial sum의 reuse distance가 4가 되었다라고 표현하고 있습니다. 따라서, 0, 1, 2, 3의 output activation을 모두 가산 연산하기 위해서는 총 4개의 memory를 필요로 하기 때문에 만약 모든 데이터를 이렇게 연산 하게 된다면 memory를 많이 필요로 해서 부담이 되겠네요.

5.5에서는 output activation을 위한 memory의 개수를 줄이고, reuse distance를 줄여보였습니다. Input activation을 각각 두 개씩 tiling을 해서 처리를 하고 있습니다. 입력 데이터 tiling을 통해 reuse distance가 2로 증가 되었지만, partial sum의 reuse distance는 2로 줄어들었습니다.
Temporal tiling
temporal tiling은 메모리 계층 구조에서 특정 메모리보다 reuse distance를 작게 만드는게 목적이라고 합니다.
예시를 이해하기 위해 아래의 그림을 그려봤습니다.
책의 예시에서는 3개의 데이터 저장 공간이 있는 L1 Memory를 기준으로 예시를 들었습니다.
만약 위와 같은 공간의 L1 Mem을 가진 memory hierarchy에서 5.2(c)와 같은 ordering을 적용하면 어떻게 될까요?
이러한 경우에는 weight만이 temporal reuse가 가능하지만, partial sum이 총 4개가 필요합니다. 따라서 필요한 L1 Mem은 총 5개이므로 partial sum들은 더 높은 계층의 memory에 저장되고 불러와서 사용되어야 합니다. 이렇게 되면 partial sum이 더 높은 계층의 memory에서 오기 때문에 transfer cost가 증가하게 됩니다.
하지만 위의 5.5와 같이 tiling을 하게 되면 weight와 partial sum 모두 L1 Mem에 저장할 수 있으므로 위에서 가정한 저장 공간이 3개가 있는 Memory로 충분히 연산이 가능해집니다. 하지만 5.5는 5.2(c)에 대비해서 source mem에서 L1 mem으로 weight를 읽는 양이 두 배가 된다는 단점이 생기네요. 이런 것 모두 trade off로 architecture를 잡을 때 고려해야 할 요소입니다.
Spatial tiling
반면에 spatial tiling의 경우 다음에 중점을 둔다고 합니다.
- 같은 데이터가 더 많은 consumers(PE)들에서 재사용이 되고,
- 메모리가 고정된 상황에서 reuse distance를 줄여 한 번 데이터를 전달할 때 최대한 많은 consumers에서 사용할 수 있게 한다.
라는 내용인데, 아래의 그림을 보시면 이해가 빠르실 것 같습니다.
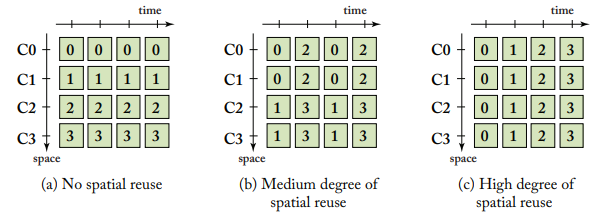
(a)의 경우 ordering이 no spatial reuse이므로, consumer들이 같은 타이밍에 받는 데이터들이 모두 다릅니다. 전혀 spatial reuse를 활용하지 못하고 있습니다. 따라서 C0~C3에게 데이터를 전달하기 위해서는 4개의 데이터 저장 공간을 필요로 합니다.
반면에 (c)의 경우 consumer들이 같은 타이밍에 동일한 데이터를 전달 받습니다. 따라서 1개의 저장공간만 있어도 모든 연산을 수행할 수 있습니다.
위에서 설명한 Temporal tiling과 Spatial tiling은 모두 고정된 memory 구조에서 가장 적합한 reuse distance를 찾아 최대한 효율적으로 연산을 수행하는데 있습니다. 매번 다양한 layer들을 연산해야 하는 DNN Algorithm을 처리하는 hardware에서는 중요하게 고려되어야 할 사항 같습니다.
만약 적당한 reuse distance를 찾았는데 다음과 같은 상황이 발생한다면 어떻게 될까요?
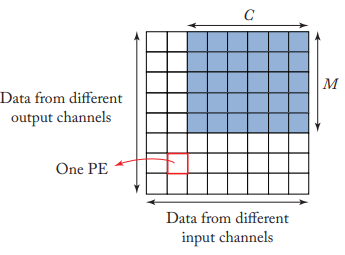
각 박스는 한 개의 PE를 M은 output channel을 C는 input channel을 의미합니다. 그림 5.7과 같은 경우에는 PE group에 비해 tile되어 처리되는 데이터가 작은 경우를 보여주는데, 이런 경우 색칠되지 않은 PE는 동작을 하지 못하는 상황이 발생합니다. 그러면 최대 성능을 낼 수 없는 상황이 발생되겠죠? 만약 최대로 성능을 내고 싶다면 한 번에 여러 tile을 연산하게 해서 놀고 있는 PE가 없게 해주어야 합니다. 이와 관련된 내용은 5.7.4절에서 다룬다고 합니다.
Tiling 기법은 서로 다른 data type(input data, weight, output data)에 별개로 적용될 수 있으며, 각 memory level에서도 서로 다르게 적용될 수 있습니다. DNN layer의 연산 방식을 고려해서 서로 다른 memory level에서 서로 다른 data type에 알맞은 tiling을 적용해야 모든 data type에 대한 access cost를 줄일 수 있습니다.
추가적으로 PE에서 연산되는 partial sum이 다른 memory level로 이동하지 않고 다른 PE에 전달 되는 내용을 언급하는데, 아래에서 언급한 내용을 포함하고 있으므로 넘어가도록 하겠습니다.
https://wh00300.tistory.com/206
Systolic array를 이용한 NPU에 대한 이해(2)
이전 글에서는 Systolic array에서 사용하는 processing element의 구조를 보았습니다. 이번에는 systolic array를 사용해서 Deep Learning Algorithm을 연산하는 대표적인 NPU인 TPU의 구조를 보도록 하겠습..
wh00300.tistory.com
마지막으로는 operation reordering과 data tiling시 bandwidth에 대한 고려사항이 있습니다.
Operation reordering을 하기 위해서는 데이터가 모두 memory에 저장되어야 하는데, 동일한 타이밍에 모든 PE에서 데이터를 한 번에 출력을 하게 된다면 memory에 보낼 데이터가 급격하게 많아지기 때문에 bandwidth가 부족해 질 수 있습니다. 따라서 평균 bandwidth보다 급격하게 많아지는 경우가 생길 수가 있기 때문에 유의해야 합니다.
또한 PE가 쉬지 않고 계속 데이터를 연산하기 위해서는 지속적으로 연산에 필요한 데이터가 공급되어야 하는데, 이 때 데이터를 가져오는 시간을 줄이기 위해 데이터를 미리 가져오는 상황이 있을 수 있습니다. 이러한 기법을 data prefetch라고 하는데 이 때 double buffering과 같은 방식을 사용한다면, 총 사용 가능한 memory에서 우리가 실제로 PE로 데이터를 보내줄 수 있는 memory의 용량이 작아지게 됩니다. 그렇다면 data reuse distance 계산 시 작아진 memory에서 효율적으로 tiling을 수행하기 위한 방법을 고려해야 합니다.
최근 조금 바쁜 일로 열심히 읽지 못해서 아쉽네요... 앞으로 더 열심히 보도록 노력해야겠습니다.
https://wh00300.tistory.com/247
Study note : Efficient Processing of Deep Neural Networks(4)
5.4 ARCHITEECTUREAL TECHNIQUES FOR EXPLOITING DATA REUSE 5.4.1 Temporal reuse Temporal reuse는 PE에서 같은 데이터를 한 번 이상 사용할 때를 의미합니다. Temporal reuse는 실제로 원본 데이터를 가지..
wh00300.tistory.com
Reference
https://www.morganclaypool.com/doi/abs/10.2200/S01004ED1V01Y202004CAC050
Efficient Processing of Deep Neural Networks | Synthesis Lectures on Computer Architecture
Efficient Processing of Deep Neural Networks Vivienne Sze Massachusetts Institute of Technology Yu-Hsin Chen Massachusetts Institute of Technology Tien-Ju Yang Massachusetts Institute of Technology Joel S. Emer Massachusetts Institu
www.morganclaypool.com
'NPU' 카테고리의 다른 글
| [OpenAI] ChatGPT를 사용해보자 (0) | 2023.02.17 |
|---|---|
| Systolic array를 이용한 NPU에 대한 이해(3) : systolic array 실험 (4) | 2022.03.20 |
| Study note : Efficient Processing of Deep Neural Networks(4) (0) | 2021.11.21 |
| Study note : Efficient Processing of Deep Neural Networks(3) (0) | 2021.11.20 |
| Study note : Efficient Processing of Deep Neural Networks(2) (0) | 2021.11.13 |


