
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- gpgpu-sim
- pygraphviz 설치 오류
- Pyverilog 실행
- Pyverilog 튜토리얼
- systolic array
- 대구 반도체 설계기업 특화
- CDC
- Makefile compile
- 컨벌루션 연산
- makefile
- 이진수 곱셈 알고리즘
- 클럭 게이팅
- 데이터 해저드
- DNN 가속기
- CUDA
- gcc 컴파일
- Pyverilog 설치
- DNN Accelerator
- CLOCK GATING
- 남산업힐
- pytest-pythonpath 설치 오류
- linux c 컴파일
- linux makefile 작성
- Pyvrilog tutorial
- Data HAzard
- linux c++ 컴파일
- 딥러닝 가속기
- Design DNN Accelerator
- AMBA
- pyverilog 설치 오류
- Today
- Total
오늘은 맑음
Systolic array를 이용한 NPU에 대한 이해(3) : systolic array 실험 본문
안녕하세요, 앞서 systolic array를 활용한 NPU에 대해서 이야기를 했었습니다.
오늘은 systolic array를 간단하게 만들어서 컨벌루션 연산을 해보는 실험을 해보겠습니다.

그림 1의 컨벌루션 연산을 수행해 볼 예정입니다.
좌측의 5x3은 입력 데이터이며, 우측의 3x3은 가중치입니다.
따라서 컨벌루션 연산을 하게 되면 총 3개의 output activation이 나오게 됩니다.
차례대로 연산을 하게 되면 output activation은 각각 312, 348, 384가 나오게 됩니다.
위의 연산을 수행하기 위해서는 총 9개의 mac 연산기를 이용해 작은 systolic array를 만들어보겠습니다.
그림 3과 같이 총 9개의 MAC연산기가 있습니다. 각 MAC 연산기에는 처음 weight가 세팅되며, input activation이 차례대로 전달되어 연산합니다. 그리고 MAC 연산을 수행한 다음 나오는 partial sum은 다음 MAC 연산기에 전달되어 최종 partial sum이 출력됩니다. 그리고 input activation을 다음 systolic array로 전달하기 위해서 오른쪽으로 출력됩니다.
실험할 데이터 플로우는 아래 그림 4와 같습니다.
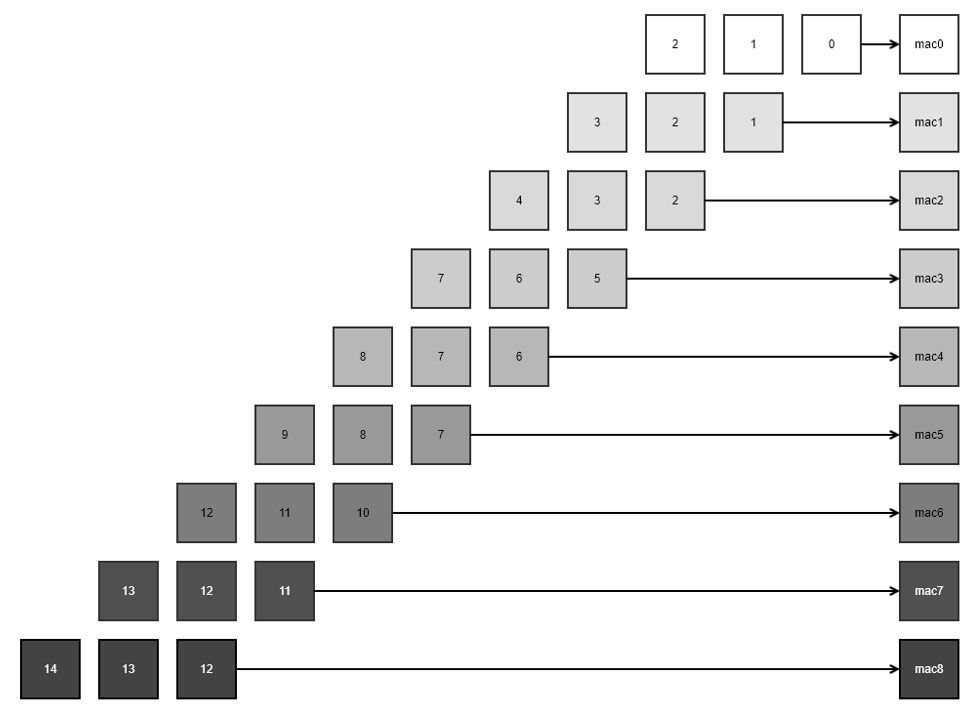
각 MAC 연산기에는 time step에 따라 데이터가 입력됩니다. 첫 번째 time step에서는 mac0에 0이 입력되어 연산을 수행합니다. 그리고 mac0의 partial sum은 mac1에 전달됩니다. 두 번째 time step에서는 mac0과 mac1에 각각 1이 입력되어 MAC연산을 수행하고 partial sum을 다음 MAC연산기에 전달합니다.
Weight는 mac0부터 mac8까지 차례대로 0~8이 고정적으로 세팅됩니다. 따라서 최종 mac8번에서는 컨벌루션 연산의 결과값이 차례대로 출력 될 것입니다. 또한 MAC0~MAC8번을 통과하면서 총 9사이클 후 부터 유효한 값이 출력됩니다.
실험의 과정 및 설명

노란색의 선으로 표기된 부분에서 negative reset이 high가 되면서 전체 모듈에 reset이 걸립니다.

다음으로는 init이 high가 되면서 초기값이 세팅됩니다. 초기값이 세팅되면서 MAC연산기에서 ready가 high로 변합니다.

다음은 weight가 입력되어 각 mac 연산기에 세팅됩니다.

그림 7에서는 input activation이 입력되면서 valid신호가 함께 입력됩니다. 따라서 ready_valid가 high로 변하면서 각 MAC 연산기가 동작하게 됩니다. 각 MAC 연산기는 세팅받은 weight와 함께 그림 4처럼 연산을 수행하게 됩니다.

차례대로 input activation이 입력되면서 내부에서는 연산이 수행됩니다.

연산이 모두 수행되면 차례대로 output activation이 출력됩니다.
각 MAC 모듈은 초기 세팅된 weight와 함께 매 time step마다 들어오는 input activation를 이용해서 연산을 수행합니다.
따라서 최종 출력값인 312, 348, 384가 각각 출력됩니다.
이번에는 weight를 고정한 weight stationary 방식을 이용해서 컨벌루션 연산을 수행하는 systolic array를 실험해보았습니다.
지금은 간단하게 1D로 구성했지만, 2D로 구성하게 되면 더 많은 데이터들을 한번에 연산 할 수 있습니다.
또한 고정하는 데이터를 바꾸고거나, partial sum의 전달 방식을 바꾸게 되면 다른 데이터 플로우를 이용해서 구성을 할 수 있습니다.
최근 다른 책들을 보느라 약간 소홀했는데, 다시 열심히 해봐야겠습니다.
https://wh00300.tistory.com/206
Systolic array를 이용한 NPU에 대한 이해(2)
이전 글에서는 Systolic array에서 사용하는 processing element의 구조를 보았습니다. 이번에는 systolic array를 사용해서 Deep Learning Algorithm을 연산하는 대표적인 NPU인 TPU의 구조를 보도록 하겠습..
wh00300.tistory.com
https://wh00300.tistory.com/195
Systolic array를 이용한 NPU에 대한 이해(1)
기존에 올렸던 글에서는 모두 adder tree를 가지는 구조였습니다. 간략하게 그리면 위의 구조였습니다. A(activation)과 W(weight)가 하나씩 입력 되면, 연산기에서 서로 곱해줍니다. 만약 5x5 컨벌루션이
wh00300.tistory.com
'NPU' 카테고리의 다른 글
| [OpenAI] ChatGPT를 사용해보자 (0) | 2023.02.17 |
|---|---|
| Study note : Efficient Processing of Deep Neural Networks(5) (0) | 2021.12.15 |
| Study note : Efficient Processing of Deep Neural Networks(4) (0) | 2021.11.21 |
| Study note : Efficient Processing of Deep Neural Networks(3) (0) | 2021.11.20 |
| Study note : Efficient Processing of Deep Neural Networks(2) (0) | 2021.11.13 |


